Kangning YinI’m a Ph.D. student at the Apex Lab at Shanghai Jiao Tong University advised by Professor Weinan Zhang. My research mainly focuses on robotics learning especially on humanoid robots.
Before that, I received my Master's degree from ShanghaiTech University, where I was advised by Professor Email / GitHub / Google Scholar / |

|
ResearchMy research interests lie in humanoid robot control, navigation, character animation, 3D human motion generation and motion retrieval. My long-term goal is to bring humanoid robots into everyday life. '*' indicates equal contribution. |
|
|
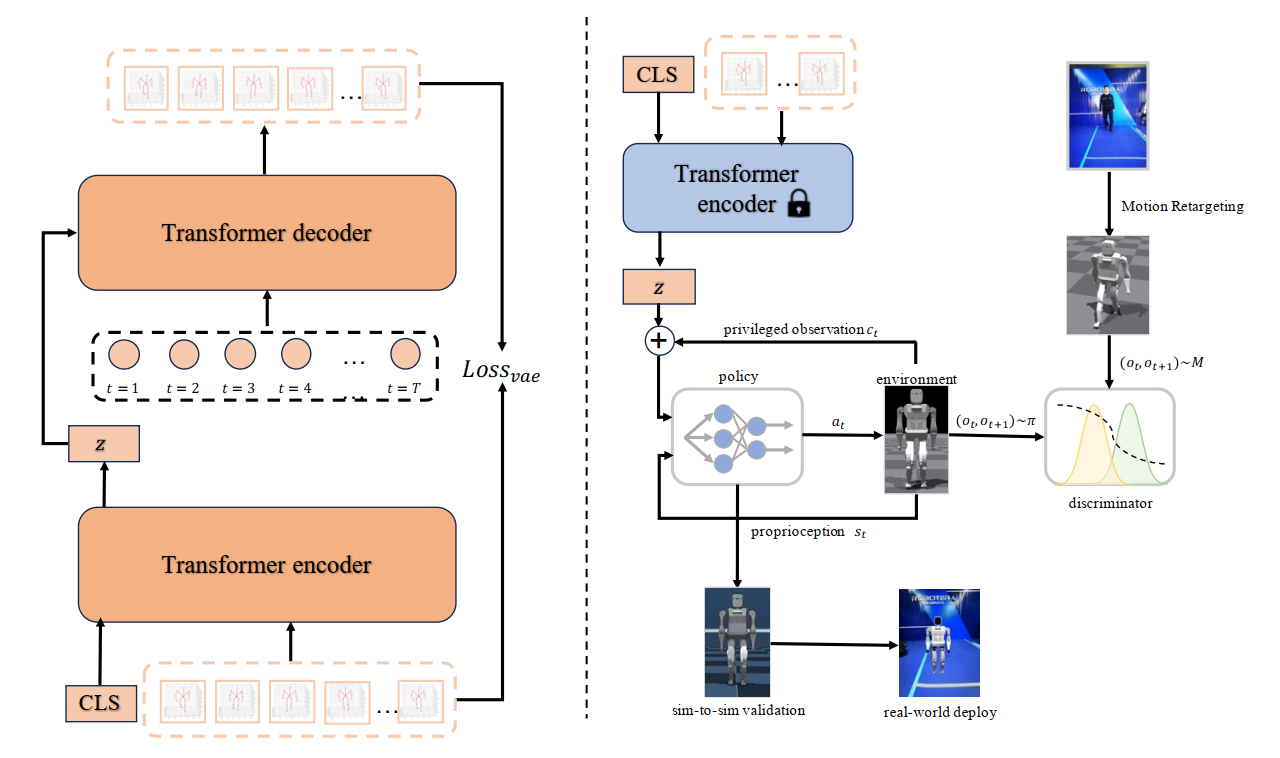
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid RobotsKangning Yin*, Weishuai Zeng*, Ke Fan, Zirui Wang, Qiang Zhang, Zheng Tian, Jingbo Wang, Jiangmiao Pang, Weinan Zhang In Submission, 2025 webpage / arxiv / paper / We present UniTracker , a unified framework for whole-body motion tracking in humanoid robots. Our three-stage pipeline consists of: (1) a privileged teacher policy for high-fidelity tracking and data curation; (2) a CVAE-based student policy for robust deployment under partial observations by modeling motion diversity and global context; and (3) a lightweight residual decoder for rapid adaptation to dynamic or out-of-distribution motions. |
|
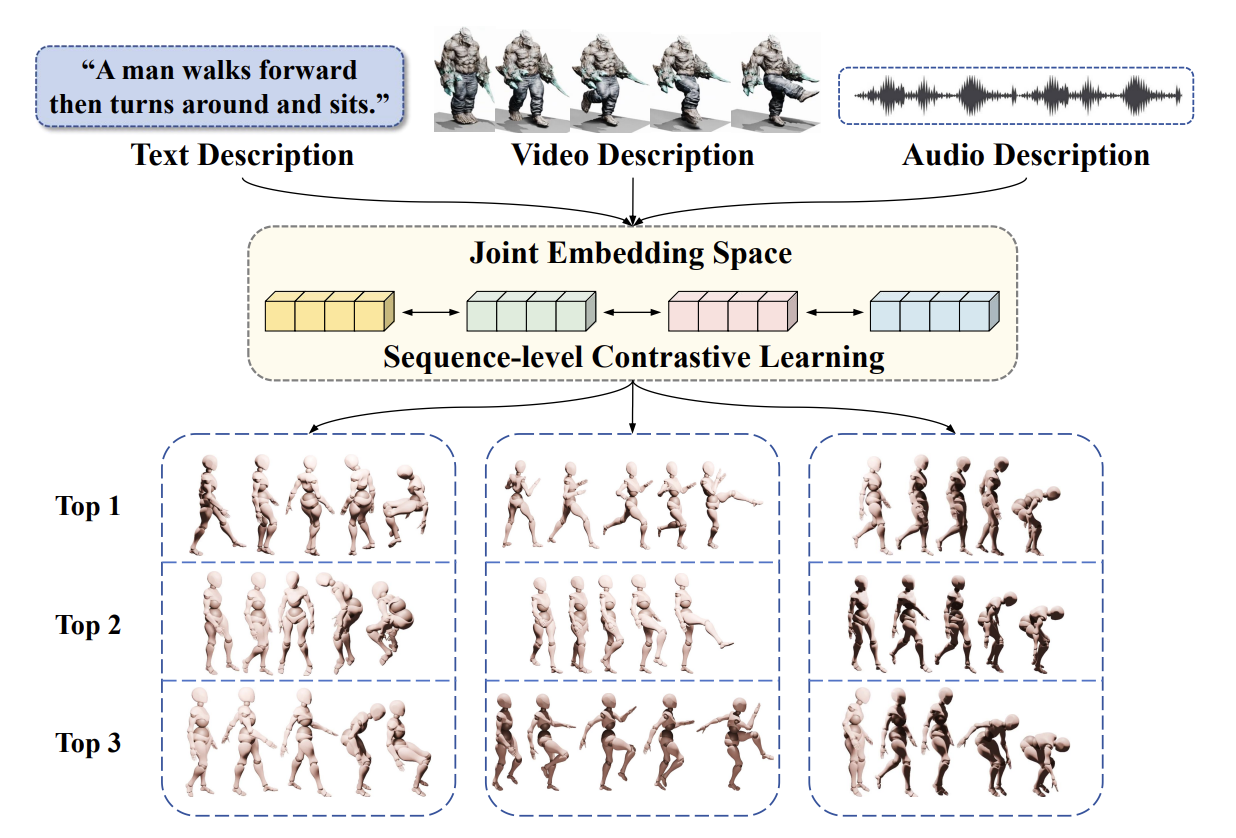
Multi-Modal Motion Retrieval by Learning a Fine-Grained Joint Embedding SpaceShiyao Yu, ZiAn Wang, Kangning Yin, Zheng Tian, Mingyuan Zhang, Weixin Si, Shihao Zou IEEE TMM 2025 (JCR Q1), 2025 arxiv / We propose a four-modal motion retrieval framework that jointly aligns text, audio, video, and motion via sequence-level contrastive learning. By introducing audio and constructing new multimodal datasets, our method achieves substantial improvements over state-of-the-art baselines, demonstrating the potential of multimodal retrieval for advancing motion acquisition. |
|
Agile Humanoid Locomotion by Learning from Human DemonstrationsKangning Yin, Yingguang Xing , Yao Mu, Jianyu Chen, Zheng Tian Under Review, 2025 paper / video / We develop a motion optimization pipeline that refines motion capture data by explicitly considering the robot’s joint limits and torque constraints, ensuring the generation of physically feasible reference trajectories. Additionally, we propose an Autoencoder-based latent representation scheme that encodes expert demonstrations into privileged observations for cumulative reward estimation. |
|
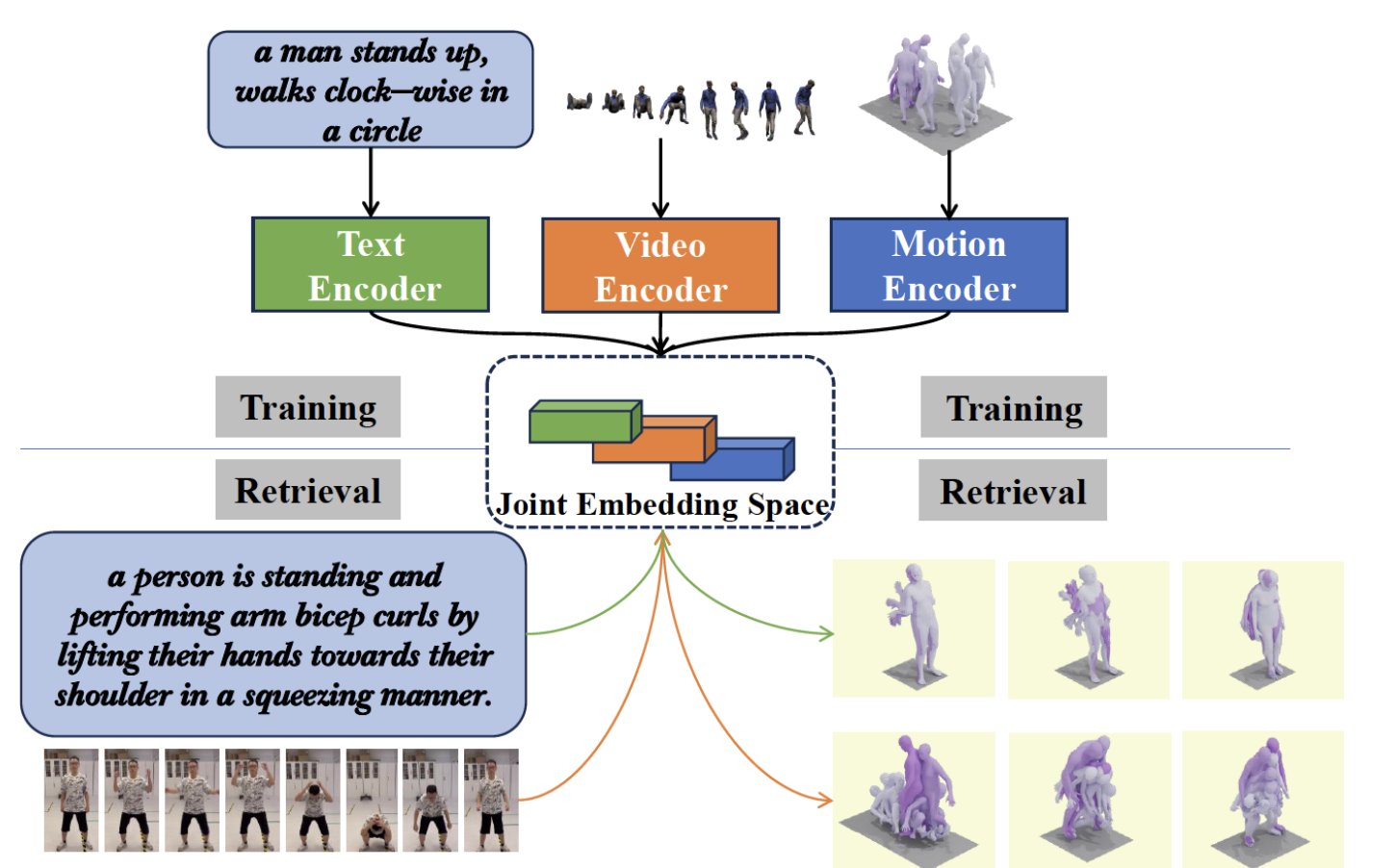
Tri-Modal Motion Retreival by Learning a Joint Embedding SpaceKangning Yin, Shihao Zou, Yuxuan Ge , Zheng Tian CVPR (Highlight), 2024 webpage / arxiv / paper / we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. |

|
RACon: Retrieval-Augmented Simulated Character Locomotion ControlYuxuan Mu, Shihao Zou, Kangning Yin, Zheng Tian, Li Cheng, Weinan Zhang, Jun Wang ICME (Oral), 2024 arxiv / We introduce an end-to-end hierarchical reinforcement learning method utilizes a task-oriented learnable retriever, a motion controller and a retrieval-augmented discriminator. |
|
Design and source code from Leonid Keselman's website |